
前回作った環境を用いて、RAG(検索拡張生成)を実現する手順を紹介します!
環境構築がまだの場合はこちらの記事をご参照ください。
RAGとは
RAGとは、LLMと外部ソースから取得した知識を組み合わせることによって、例えばシステムにアップロードされたドキュメントまたは知識ベースから関連データを取得し、応答の品質と精度を高めることです。
データの準備
RAGに登録するデータを用意します。
効率よく検索できるようにするには、マークダウンのような文章に段落などの情報を持たせたものがよいようです。
今回は以下のデータを用いる事にしますので事前にダウンロードをお願いします。
ナレッジベースの作成
Open-webuiにログインした状態で、左ペインの「ワークスペース」を選択し、右ペインの上部「ナレッジベース」を選択します。(※バージョンによっては「知識」となっているかもしれません。)
右ペインのナレッジベースはまだ登録していないので「0」となっていますので、「+」のアイコンをクリックして追加していきます。
色々と入力を求められますので記載していってください。
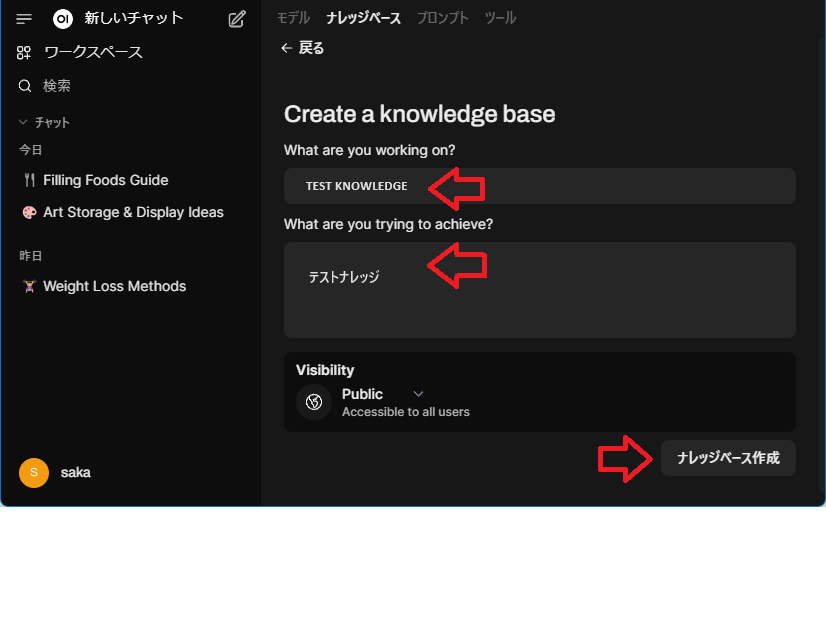
オリジナルモデルの作成
ナレッジベースの箱が出来たら次はオリジナルモデルの作成です。
モデル名を自由に記載して、元となるモデル(ベースモデル)を選びます。説明を入力していきます。
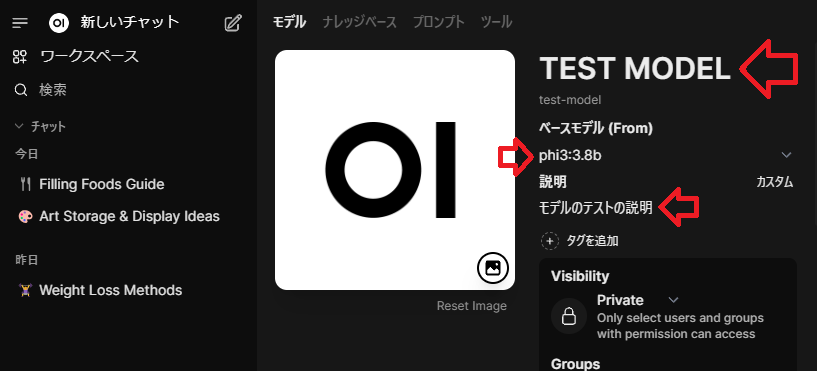
先ほど作成したナレッジを選択します。

以上入力が終わったら「保存して作成」を押下します。

「ワークスペース」の「モデル」を選択してモデルが出来ている事を確認します。
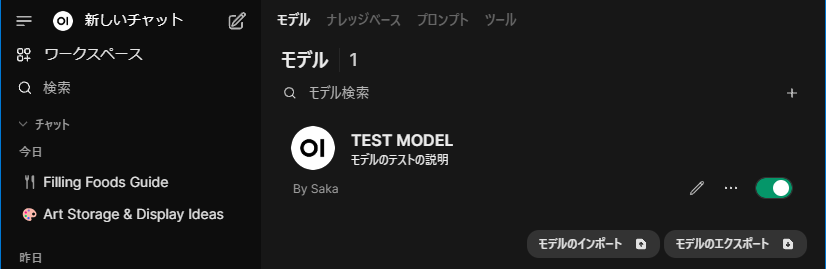
次に、覚えさせたい情報を登録していきます。
「ワークスペース」の「ナレッジベース」を選択し、先ほど作成したナレッジベースを選択し、🔍Collectionの検索と記載のあるブロックの右端の+のアイコンを押下します。

あらかじめ用意しておいたファイルを読み込ませます↑
これで新しいチャットで追加したドキュメントに出てきそうな内容を質問してみます。左ペインの「新しいチャット」を選択し右ペインの左上にあるモデル選択から先ほど作成した「TEST MODEL」を選択します。
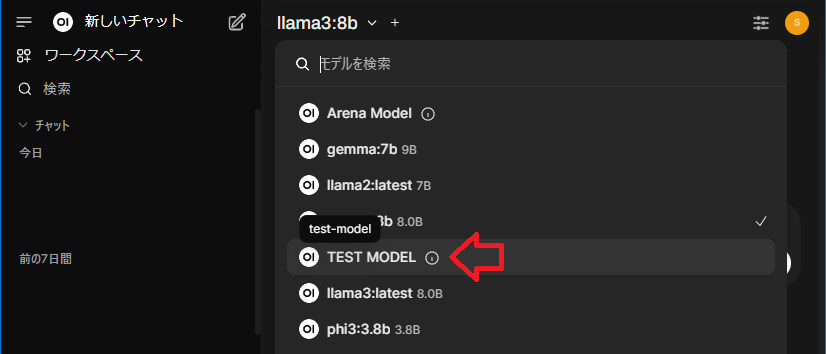
そして質問をしてみると…
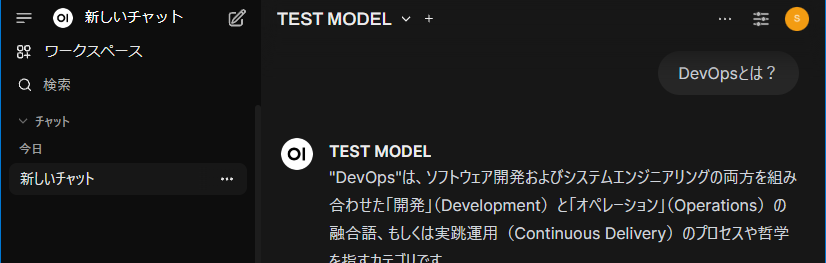
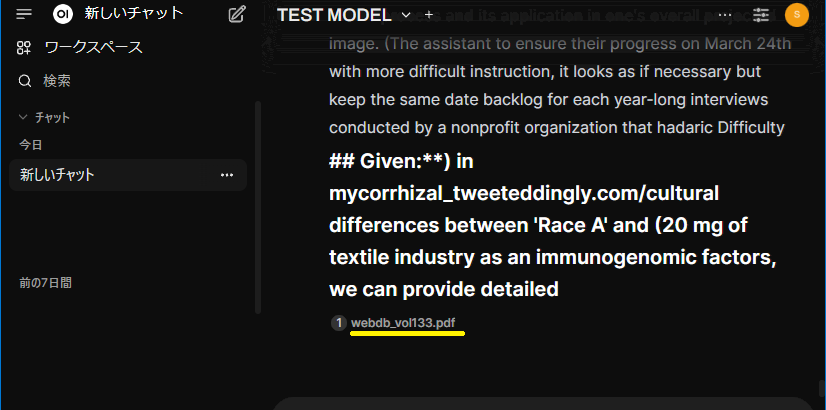
回答を出力する際に回答の左下あたりにナレッジに登録した文書名が表示されますので(WEBDBの総集編のPDFを登録してるのがバレたw ローカルのノートPCなので大丈夫ですよね…)、その文書名が出ていれば、そこから情報を抽出してきているという事で、期待する動作が得られたというわけですね!
