$ git clone https://github.com/langgenius/dify.git
$ cd dify/docker/
$ cp .env.example .env
$ vi .env
PCのポート80と、443は使われているという場合、.envのNGINX_SSL_PORTと、EXPOSE_NGINX_PORTの値を以下のように変更します。
$ diff .env.example .env
991,992c991,992
< EXPOSE_NGINX_PORT=80
< EXPOSE_NGINX_SSL_PORT=443
---
> EXPOSE_NGINX_PORT=8080
> EXPOSE_NGINX_SSL_PORT=8443では起動します
$ docker-compose up -dブラウザで http://localhost:8080/ でアクセスするとDifyにつなぐことが出来ます♪
LLMを使えるようにする
画面右上のアカウントアイコンをクリックして「設定」を選択する。
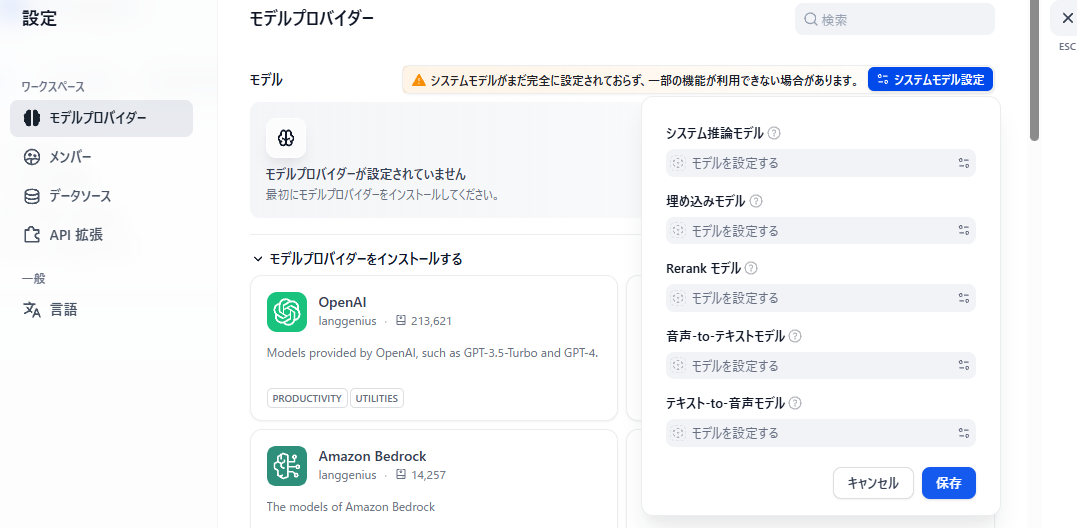
モデルプロバイダーを選択すると、システム推論モデル他、モデルが設定されていないのが確認できる。
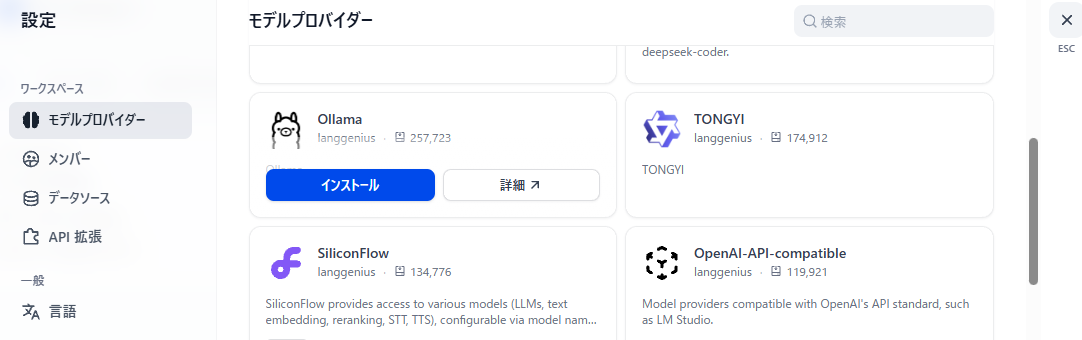
今回はローカルで動作するOllamaに接続させて試験するため、まずはOllamaをインストールする。
Ollamaの右下の「モデルを追加」を押下する
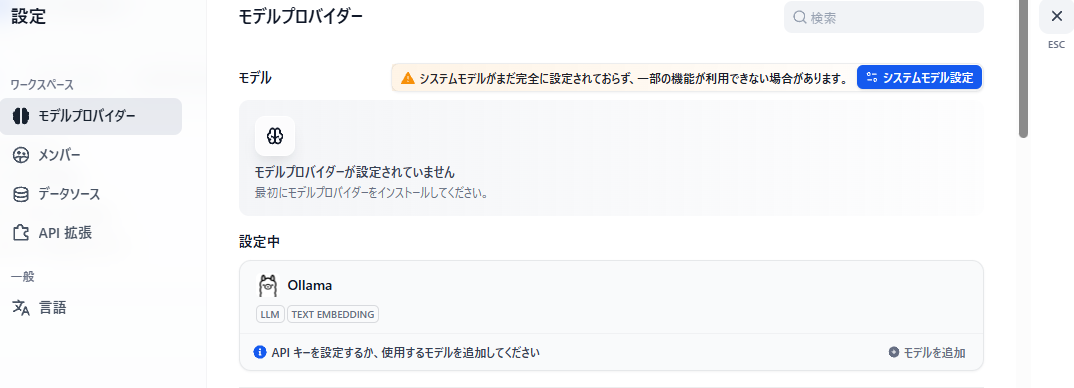
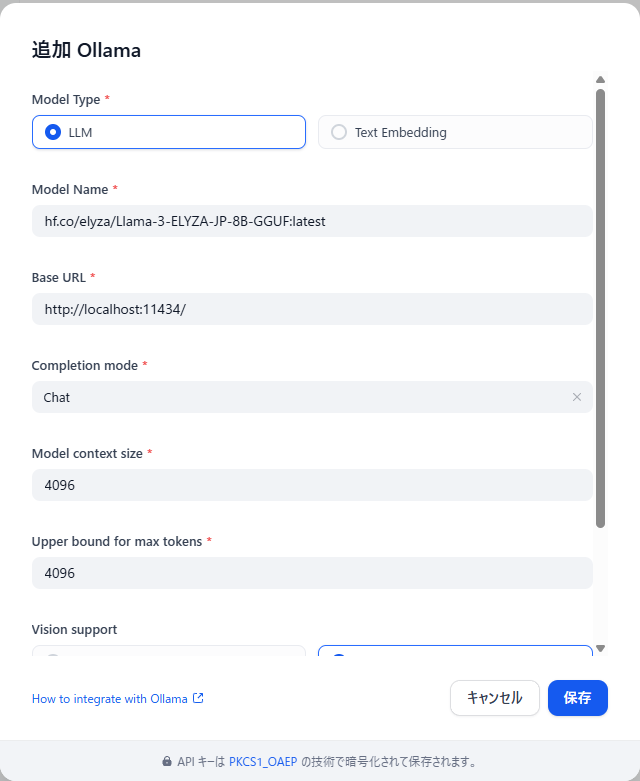
LLMのモデル名と、ollamaが起動しているサーバ(ここではローカルホストと想定)を指定する
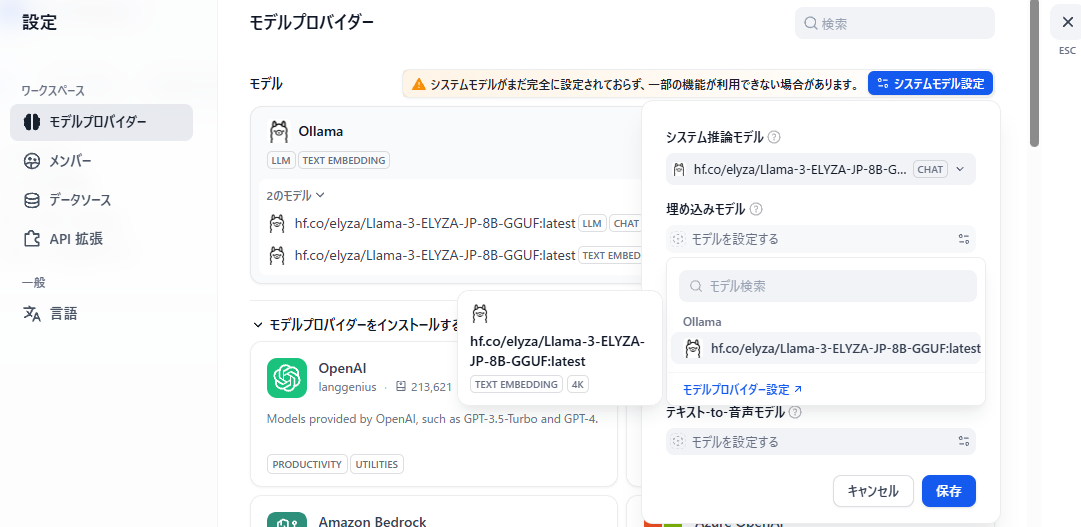
システムモデル設定を実施する。
先ほど登録したOllamaをシステム推論モデルとして選択する。
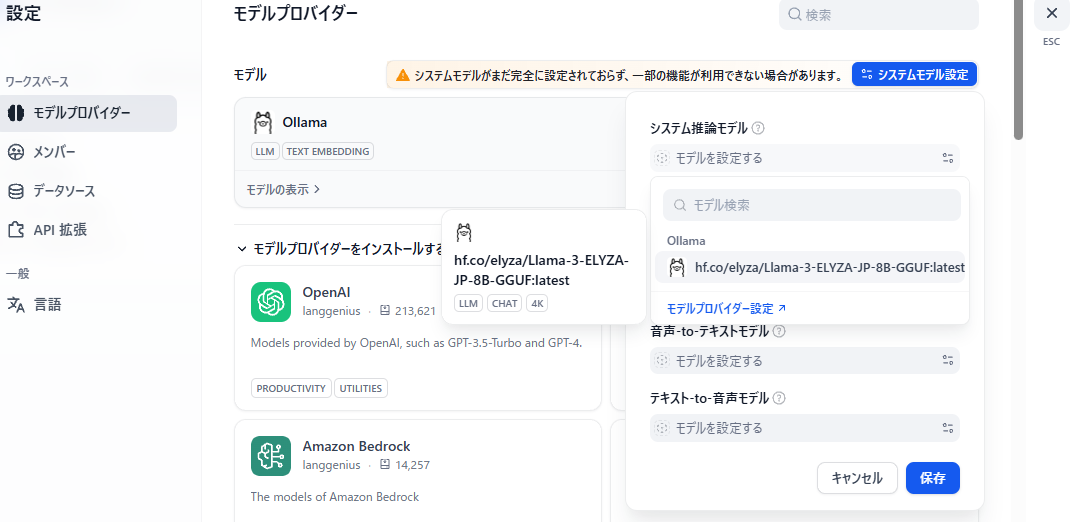
同じくText Embeddingも、登録したOllamaのモデルを利用する。
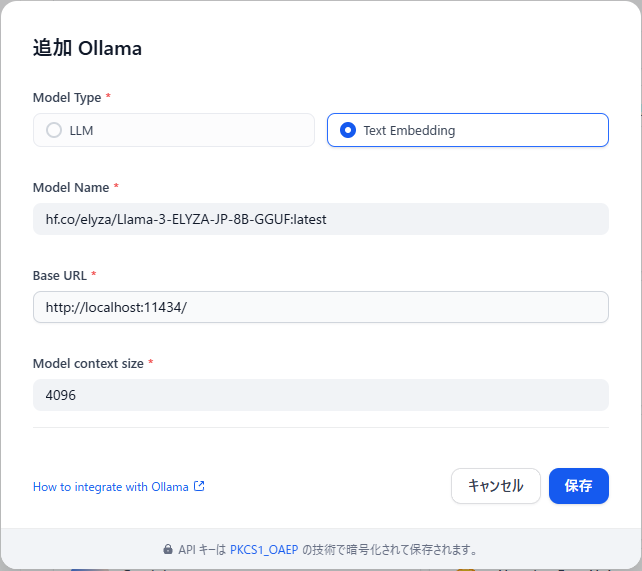
これで、埋め込みモデルが選択できるようになっています。
ひとまずここまで出来たら、前回のRedmineのツールをインストールしてRedmineをDifyから操作できるところまで作れるようになってると思います。
入力や出力に音声を用いる事で、更に利便性が向上します。
テキストを読み上げしてくれるツールをTTS(Text to Sound)といい、その逆に音声をテキストに変換してくれるツールをSTT(Sound to Text)といいます。
システムモデルとして設定として、これら2つを登録しておくことでDifyでも入出力に使えるようになります。
TTSで無償で利用できるものとして様々な声が選べるVOICEVOXという物があります。
STTはクラウド提供など有料のものは沢山あるのですが、ローカルで無償で使えるものは見つけられてません…どなたか教えてください orz...
TTSなVOICEVOXを使う場合は以下をインストールして、あらかじめ起動しておいたVOICEVOXサーバを指定するのみ。
VOICEVOXサーバのセットアップは別途書く
プライベート環境で、外部に出ていくためにはPROXYを経由しなければならないという環境で利用する場合は、基本各コンテナ郡はssrf_proxyを参照する動作となっています。ssrf_proxyでは、squidが動いており、./docker/ssrf_proxy/squid.conf.template を読み込んむ動作となっています。
このsquid.conf.templateで cache_peer を設定することでプライベートや、コンテナ通信はssrf_proxyで折返しそれ以外のツールなどのダウンロードはcache_peerで設定された上位のProxy経由とするといった設定をすることで解決できると思います。(会社の環境ではそのように設定しております)